

Minimind本地部署+训练
本项目介绍一个minimind在单4090设备上进行快速部署(docker)的案例(2025-04-02):

一.环境配置
- clone项目
直接git拉取代码:
git clone https://github.com/jingyaogong/minimind.git - docker:
由于作者没提供docker,所以先查看minimind的环境要求,发现是torch2.2.2,所以去nvidia pytorch官方镜像页寻找一个合适的:


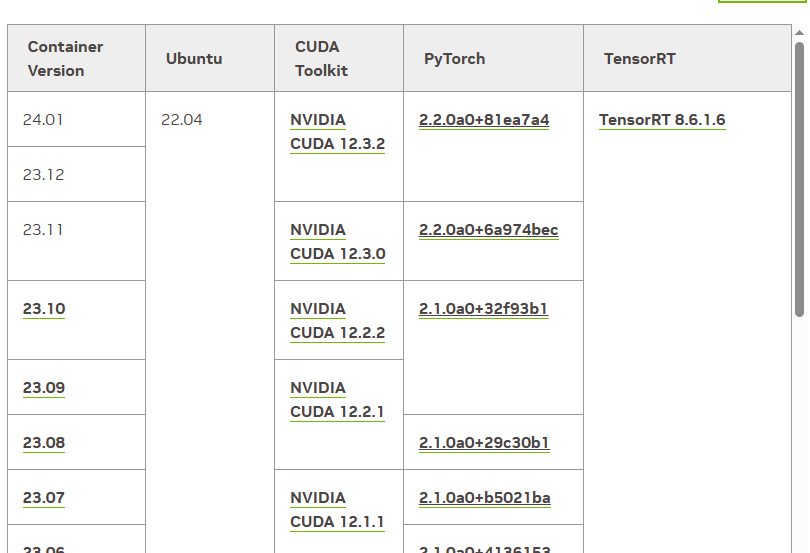
选择完成后直接进行docker run:
docker run --gpus all -it --name minimind -v /opt/minimind:/minimind nvcr.io/nvidia/pytorch:24.01-py3 等待完成,进入容器。
- 安装第三方依赖
pip install -r requirements.txt- 下载数据集:
使用作者提供的modelscope方式:

创建一个dataset文件夹,选用[第三种命令行方式]()下载, local_dir指定下载位置:
modelscope download --dataset gongjy/minimind_dataset README.md --local_dir ./dir
没有modelscope的pip安装一下: pip install modelscope

等待下载完成,修改文件夹名字 dataset:

二. 训练
由于我们是从头开始训练,所以按照作者提供的步骤进行,这里要注意minimind zero是可以实现快速训练,也即标题中声称的2小时。



根据作者提供的参数参考,直接进入LMconfig.py更改参数:

这里对于MiniMind2不同的name,代表的参数很清晰,比如MoE设置为1+4很容易猜到是4个专家,这样参数量对应增加,下方的v1表示最近采用了deepseek的FFN层处理方式,也即结构区别不仅仅是参数不同,所以名称也有所区别。所以作者说的zero就代表了第一行的参数设置,第三行表示需要加上后续的full sft。config中也可以看到具体的参数设置:

1. 预训练(Pretrain)
先按照MiniMind2-small最小的来一次:
直接运行:
python train_pretrain.py
等待。。。由于只有1个epoch,非常轻松,结束了可以看到保存后的权重文件:
2. 有监督微调(Supervised Fine-Tuning)
直接还是跑最小的,对应修改即可:

直接运行:
python train_full_sft.py经过不漫长的等待,可以查看到训练完成后的权重:

2.5. 验证训练结果
首先将刚才的out改个地址,我将默认的输出地址out改为out_2025_04_02_minimind2-small-0.025B,保留备份:

然后直接使用参数执行测试:

python eval_model.py --out_dir out_2025_04_02_minimind2-small-0.025B
好,看回答基本等于能说点人话。
到这完成了基本的训练。
3. 人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)
ok,完成了全参数的有监督微调以后,其实这里大模型已经可以使用,但是这里需要进行RLHF,也即使用人类的反馈进一步强化学习,这里大佬hinton给了一个比喻,大模型相当于一个满是漏水的大坝,RLHF就相当于用手指头不断的堵漏,属于是没办法的办法。但不管怎么说目前RLHF是保证大模型交互(一问一答)的一个重要步骤:
使用train_dpo执行,此时注意代码中的路径,之前修改过out则需要修改路径或者修改代码保持一致:
训练结束,生成一个文件:

可以发现到此一共三个权重文件,很清晰。
测试一下:
python eval_model.py --out_dir out_2025_04_02_minimind2-small-0.025B --model_mode 2
比刚才稍微好点!
4. 知识蒸馏(Knowledge Distillation, KD)
其实到上一步已经结束了,只是,为了进一步让大模型表现更好,体积更小,可以进行模型蒸馏,这里作者解释的很好

简单的说就是蒸馏目前因为用法问题分为了两种路线,黑盒/白盒蒸馏,目前最普遍的做法是面向超大参数的模型的输出进行直接的训练,也就是依照的分类标签进行监督,也就是黑盒做法,简单直接,这里其实就是做了一次额外的sft。当然接下来作者说了,由于minimind没有更大的模型,所以还不能做白盒蒸馏,但是也给出了代码来学习!
所以这里还是不继续在0.025B上继续做sft了,除非使用更大的预训练模型比如0.1B。
5. LoRA (Low-Rank Adaptation)
低秩微调也是现金生成式模型重要的手段,尤其是大参数量模型,全量微调奢侈昂贵又容易学废,所以对于专有领域的知识,私有知识等,LoRA是一个非常好的手段(一般比RAG要好),这里作者提供了两个lora的小型数据集,也是简短的问答对,这里使用医疗数据进行lora微调:
python train_lora.py --data_path ./dataset/lora_medical.jsonl6.训练MiniMind2-0.1B
python train_pretrain.py --epochs 2 --dim 768 --n_layers 16三. 测试
我们使用minimind的初衷除了学习之外,更多的是在于如何应用,也即当一个LLM体积够小,就具备了一些边缘硬件计算的潜力,为一些应用产品的开发提供了可能性,所以,对于CPU能力是一个重要的指标:
这里测试一下刚才的0.025B的minimind2-small的效果:
python eval_model.py --out_dir out_2025_04_02_minimind2-small-0.025B --model_mode 2 --device cpu由于桌面CPU的效率还是很高的,所以速度几乎无差别,小模型到了几百MB量级,通过一定的模型转换(onnx tensorRT),在CPU中的处理效率一定是很高的,并且minimind是从0开始的pytorch编程,没有用任何第三方优化库,也方便移植。
后续待测:
- 模型转换
- 移动端cpu

 Dify图像处理-自动背景去除(workflow部分) - 不负芳华
[…] ok 首先参照Dify + deepseek搭建工作流进行dify的本地部署(本文不做云端的尝试),默认部署成功通过本地直接进入dify应用页面http://localhost/app,后直接创建空白模版: […]
Dify图像处理-自动背景去除(workflow部分) - 不负芳华
[…] ok 首先参照Dify + deepseek搭建工作流进行dify的本地部署(本文不做云端的尝试),默认部署成功通过本地直接进入dify应用页面http://localhost/app,后直接创建空白模版: […]
 lizedong
感谢您的贡献
lizedong
感谢您的贡献
 下水草牛
博主您好,这个教程更细节https://ccnphfhqs21z.feishu.cn/wiki/EH6wwrgvNiU7aykr7HgclP09nCh
下水草牛
博主您好,这个教程更细节https://ccnphfhqs21z.feishu.cn/wiki/EH6wwrgvNiU7aykr7HgclP09nCh